
Microsoft ja Sony pääsivät sopuun Call of Dutystä
Lisäksi: ChatGPT:een kooditulkilla voi skaalata vaikka reseptejä


Päivää! ☕
Kesälomalla oma aikatauluni ei ole ihan yhtä kiveen hakattu kuin arkena, joten Transistorinkin ilmestymisaika saattaa heitellä normaalista huomattavasti. Koitan saada seuraavan uutiskirjeen julkaistua torstaina.
Transistori on (normaalisti) arkiaamuisin ilmestyvä teknologiauutisiin ja internet-kulttuuriin keskittyvä uutiskirje, jota sponsoroi ohjelmisto- ja datakonsultointipalveluja tarjoava Three Point Consulting. Klikkaa Transistori tilaukseen ja pysy kartalla teknologiamaailman tuoreimmista käänteistä!
Uutiset 🗞️
Microsoft ja Sony pääsivät sopuun Call of Dutystä
Microsoft ja Sony ovat päässeet sopuun Call of Duty -pelisarjan (CoD) jatkosta Sonyn PlayStation -konsoleilla, Microsoftin suunnitellun Activision -kaupan toteutuessa. Asiasta kertoi mm. Microsoftin Xbox-divisioonan johtaja Phil Spencer Twitterissä:

The Vergen tietojen mukaan aiesopimuksen myötä Microsoft sitoutuisi julkaisemaan CoD -pelejä PlayStationille seuraavan kymmenen vuoden ajan, tehden siitä hyvin samanlaisen kuin Microsoftin ja Nintendon aiemmin solmima aiesopimus CoD -peleistä:
While Microsoft’s initial announcement doesn’t mention 10 years for Call of Duty on PlayStation, Kari Perez, head of global communications at Xbox, confirmed the 10-year commitment to The Verge. Perez later confirmed to The Verge that the deal is only for Call of Duty, though. That makes the deal similar to a 10-year agreement between Microsoft and Nintendo, but not the various deals Microsoft has struck with Nvidia and other cloud gaming platforms to bring Call of Duty and other Xbox / Activision games to rival services.
Sonyn ja Microsoftin välisestä sopimuksesta uutisoitiin noin viikko sen jälkeen kun Yhdysvaltalaistuomioistuin eväsi maan kauppakomission FTC:n pyynnön lykätä yrityskaupan hyväksymistä.
Kaupan ainoa este tällä hetkellä on Ison-Britannian kilpailuviranomainen CMA, joka vaati sen estämistä aiemmin keväällä. CMA:kin tosin ilmoitti viime viikolla, että on valmis arvioimaan yrityskaupan ehtoja uusiksi.
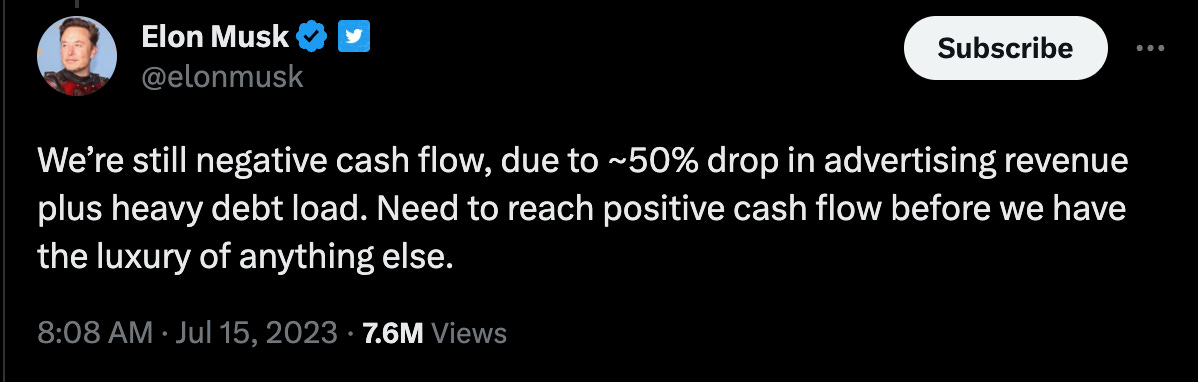
Twitter kamppailee yhä negatiivisen kassavirran kanssa
Elon Musk jakoi viikonloppuna Twitterissä tietoa yhtiön taloudellisesta tilasta. Muskin mukaan yhtiön kassavirta on edelleen tappiollista ja siihen on vaikuttanut yhtiön mainostulojen merkittävä n. 50 % lasku. Yhtiön ensisijainen tavoite onkin kassavirran muuttaminen positiiviseksi:
Teknologiamaailman suurin uutinen on viimeiset kaksi viikkoa ollut Metan julkaisema Twitter-klooni Threads, joka sai ennätyksellisessä ajassa 100 miljoonaa käyttäjää.
Tesla aloitti Cybertruckien valmistuksen
Mainitaan vielä, että Tesla on aloittanut Cybertruck -lava-autonsa valmistuksen yhtiön Teksasin tehtaalla. Auto esiteltiin alunperin vuonna 2019. Wall Street Journalilta (WSJ):
Tesla built the first Cybertruck at its factory in Texas, rolling out the futuristic electric pickup nearly four years after the prototype was introduced.
The company celebrated the production kickoff in a Saturday morning tweet that showed a photo of the vehicle surrounded by hundreds of employees in hard hats at Tesla’s plant in the Austin area, where the company is now based.
Musk unveiled the Cybertruck in 2019 at an event outside of Los Angeles, and suggested at the time that it would be in production within a couple of years.
Suosittelut 🕵️
ChatGPT:een kooditulkilla voi skaalata vaikka reseptejä
OpenAI julkaisi ChatGPT Plus -tilaajille ns. kooditoiminnallisuuden (eng. Code Interpreter eli CI) heinäkuun alussa ja olen sitä itse käyttänyt mm. reseptien skaalaamiseen. Uuden toiminnallisuuden myötä ChatGPT:llä on pääsy serverille jossa pyörii instanssi Python-ohjelmointikielestä ja tietty määrä sen valittuja kirjastoja. Yksi näistä kirjastoista on optiseen tekstintunnistukseen käytetty OCR-kirjasto Tesseract. CI-työkalun myötä ChatGPT:lle voi antaa myös tiedostoja kuten vaikka .jpeg -muodossa olevia kuvankaappauksia.
Alla on aineslista New York Timesin korealaisten lihapullien reseptille. Ainekset on listattu imperiaalisen mittayksikön mukaan, eli kilojen sijasta paino ilmoitetaan paunoina jne.

Lataan kuvan ChatGPT:lle ao. syötteen kanssa, minkä jälkeen tekoälyohjelma alkaa prosessoimaan pyyntöäni:
You have access to the Python OCR-package tesseract. Please OCR the following image, which contains a list of ingredients for a dish. The units of the ingredients are in the imperial system. I've got 1.5 kg of beef. I want you to scale the recipe based on the amount of beef I have and convert all the units to the metric system.
ChatGPT tuottaa ajonaikaiseen ympäristöön koodin, jonka serveri suorittaa. Tässä tapauksessa python koodin pätkä näytti tältä:
# Define the conversion factors
pound_to_kg = 0.45359237
cup_to_liters = 0.236588
tbsp_to_liters = 0.0147868
tsp_to_liters = 0.00492892
# Define the original amount of beef in the recipe in kg
original_beef_kg = 1 * pound_to_kg
# Define the amount of beef the user has in kg
user_beef_kg = 1.5
# Calculate the scaling factor based on the amount of beef
scaling_factor = user_beef_kg / original_beef_kg
# Define the original amounts of the ingredients
original_ingredients = {
"beef": [1, "pound"],
"Ritz crackers": [0.5, "cup"],
"scallions": [0.5, "cup"],
"soy sauce": [2, "tablespoons"],
"minced garlic": [2, "tablespoons"],
"kosher salt": [1, "teaspoon"],
"black pepper": [1, "teaspoon"],
}
# Convert the units to the metric system and scale the recipe
scaled_ingredients = {}
for ingredient, (amount, unit) in original_ingredients.items():
if unit == "pound":
amount_metric = amount * pound_to_kg
elif unit == "cup":
amount_metric = amount * cup_to_liters
elif unit == "tablespoons":
amount_metric = amount * tbsp_to_liters
elif unit == "teaspoon":
amount_metric = amount * tsp_to_liters
else:
raise ValueError(f"Unrecognized unit: {unit}")
# Scale the recipe
amount_scaled = amount_metric * scaling_factor
# Store the scaled amount and its unit
scaled_ingredients[ingredient] = [amount_scaled, unit]
scaled_ingredientsJa lopulliset ainemäärät olivat ohjelman mukaan nämä (tarkistin tuon Ritz -keksien määrän ja se oli ainakin oikein):

Malli ei ole omien kokeilujen mukaan kuitenkaan täydellinen. OCR-prosessi eritoten on huono erottamaan tiettyjä murtolukuja ja se sekoittikin usein luvut 1/4 ja 1/3 keskenään.
OpenAI on myös toistaiseksi dokumentoinut hämmentävän huonosti mitä kaikki paketteja esimerkiksi koodi-instanssiin on asennettu. Kuulin itse esimerkiksi serverin OCR-kyvykkyyksistä vasta Swyxin Latent Space -podcastissa. Samassa podcastissa mainitaan, että tuo CI-instanssiin pääsyn omaava malli tuntuu olevan normaalia GPT-4:ää kyvykkäämpi.
Nopeet 🚀
(€) Netflixin käyttäjäkasvu nousi nyt myös Yhdysvalloissa.
Hamel Husseinilta erinomainen esitys luettavasta ja tutkivasta ohjelmoinnista.
Applen Vision -tiimissä näyttää tapahtuneen uudelleenjärjestelyä.
Norjan tietosuojavaltuutettu haluaa Metan lopettavan kohdistetun mainonnan mm. Instagramissa.
Analyysiä siitä miksi ydinvoiman rakentaminen maksaa niin paljon.
Kauppatieteiden professori Ethan Mollickin opas luovan tekoälyn käyttöön työpaikalla.
Sciencessä tutkimusta kielimallien vaikutuksista ihmisten tuottavuuteen.
(€) Ilmeisesti uusi tuottavuustrendi on striimata omaa työntekoa tuntemattomille (???)